I was also thinking about Pandoc which can also parse and output a whole bunch of formats. It could be interesting for other types as well.
Got the basics working with minimal changes to the core. I had to add the .tex extension and mime type to the respective lists in action.py and report.py. Also in report.py I needed a small change in the convert function in the Report class. There is a try ... catch in there and I added an if statement there so the command will be for Latex or LibreOffice
.....
try:
if input_format == 'tex' and output_format == 'pdf':
cmd = ['xelatex',
'-output-directory', dtemp, path]
else:
cmd = ['soffice',
'--headless', '--nolockcheck', '--nodefault', '--norestore',
'--convert-to', oext, '--outdir', dtemp, path]
output = os.path.splitext(path)[0] + os.extsep + oext
.....
I have to test a bit better because sometimes Latex needs more then 1 run to get things right. This seems normal behavior and some people advises to do 3 runs. The extra runs are for example needed to get different counts right like page numbers, tables and references. In my case everything was working perfectly in 1 run.
At this moment I only looked at the invoice, but it’s working well and is IMO way faster then LibreOffice which is of course a nobrainer because no heavy package is needed.
I think you can try latexmk …
1 Like
LaTeX requires an undetermined amount of run to process final output (and theorically the number of run could be infinite), because it could save data (like a page reference) and uses this data in a page before or after (put a “see at page N”). Depending the size of “N”, it could trigger a paragraph or page break, and so it could change the reference (the page number changed due to page break for example).
A tool like latexmk take care of that by running LaTeX generation while the output file change.
Personally, I would like a lot to be able to produce report with LaTeX (or other typesetting program), but LaTeX could require lot of dependencies to produce final report.
For example, we cited:
xelatex: a special flavor of LaTeX (for specific font)latexmk: a tool for building LaTeX documentlongtable: a (common) LaTeX package
I bet that more package will be need (for unicode, graphics, geometry). They are usually commons packages, but choice should be done with care to avoid unusual dependencies.
1 Like
Thanks a lot! Didn’t know about this little fellow. I had a 3 page invoice which had to be run twice to get the column widths right. Longtable uses default chunks of 20 rows and at the first run it stores the width of the colums. The second run is used to adjust the widths to be the same. And latexmk takes care of those two runs, so no need to make a lot of changes in Tryton.
Me too, it gives you a lot more control and also translations should be more straight forward because LibreOffice sometimes add extra tags in the text which cripples the translation.
There is a third one called pdflatex, which does the same as xelatex but cannot render specific fonts. Also latexmk is basically a wrapper because it can call different programs to do the job. For example rendering to a PDF, latexmk is using pdflatex. Add -xelatex to the command and latexmk uses xelatex to render the PDF. Also all the packages can be found in the default (Linux) repositories.
Absolutely. I have now 9 dependencies on Latex-packages, all are common and installed with the normal tools.
\usepackage[a4paper,hmargin=0.79in,vmargin=0.79in]{geometry}
\usepackage[parfill]{parskip} % do not indent paragraphs
\usepackage{longtable} % needed to display a multipage table
\usepackage{fp} % needed for calculating the page subtotals
\usepackage{numprint} % needed for pretty printing the amounts
\usepackage{lastpage} % needed for total pages e.g. (page 1 from 6)
\usepackage{multirow} % needed to span multiple rows
\usepackage{xltxtra} % needed for special fonts
\usepackage{eurosym} % needed for € symbol, can maybe removed as it can come from Tryton
As you can see there are a few packages which can be removed when doing a bit more work. If you don’t need the subtotals, remove the fp package, no special fonts? remove xltxtra.
I also have to apologize to @noosanon for hijacking the thread. But as you can see, it’s possible but not straight out of the box to use subtotals in reports in Tryton.
Created my own test environment and filled it with the Tryton demo data by executing tryton-tools: 16e59109a00d tryton_demo.py
Made the changes to the report side and tried to recreate the default invoice layout. So just get the layout kind of the same so no counters, font styles or other fancy stuff. I’m not a LaTeX expert but I want to share my results so far.
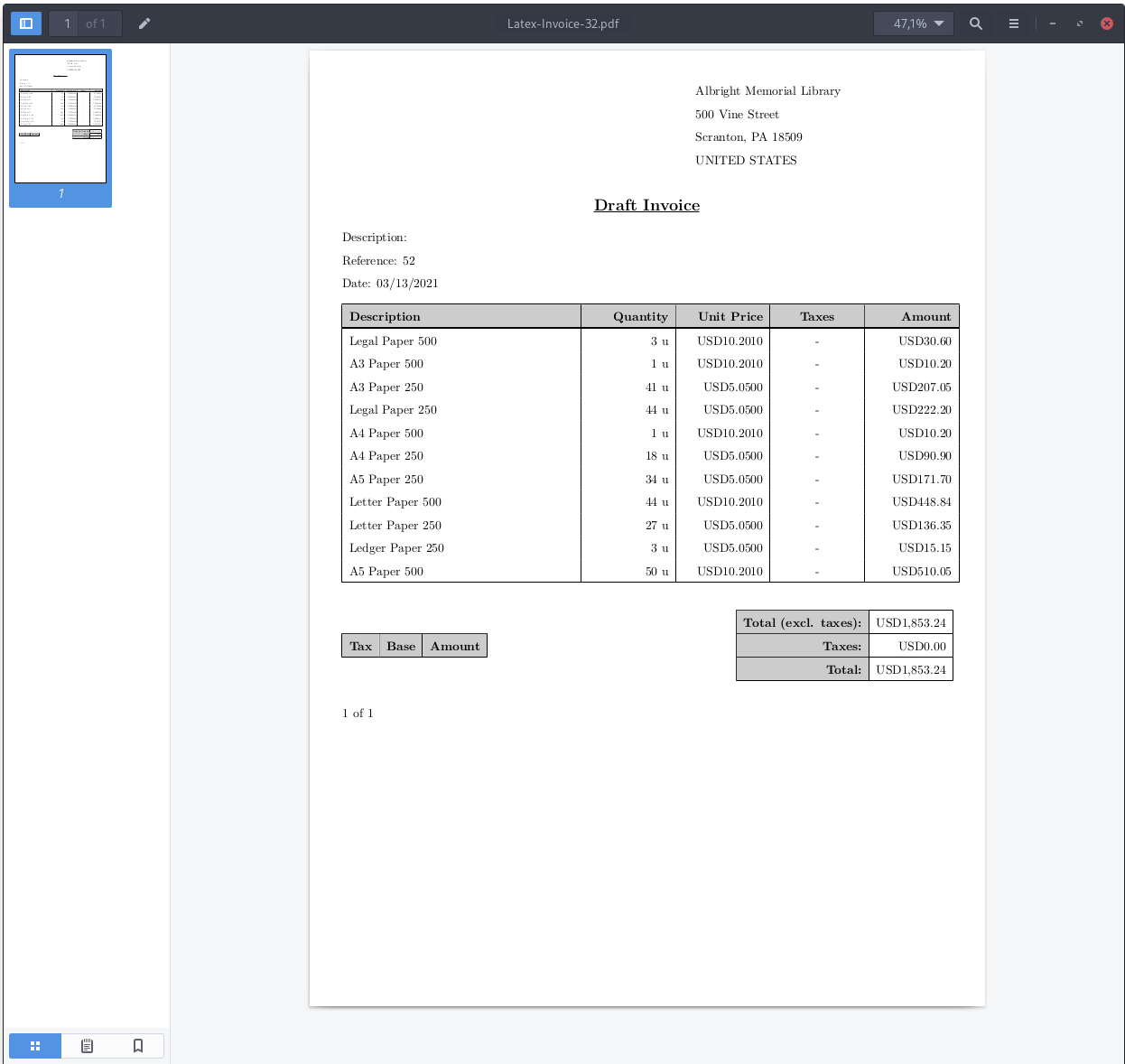
There is a small problem with how the numbers are formatted in Tryton. I’m using the function format_currency which returns the amount prefixed with the currency symbol. However the $ dollar sign means something in LaTeX and should be escaped otherwise LaTeX errors out. I’m lazy so I replaced the US$ to USD in the Tryton currencies.
I would love to share the tex-file but i’m not allowed to upload the file. Including comments it’s 155 lines long. So if you all are ok with putting it between the quotes, let me know.
I think it should be the job of relatorio to escape LaTeX special chars. $ is one, but \ is another. Else you could finish with shell escaping (which is possible if I recall correctly).
Discuss has a “hide details” formatter:
Example
This text is hidden
That’s right. I’m escaping the \\ now with another set of \\ but it would be nice if that can be prevented.
It would be nice indeed. But I didn’t go that deep into the problem because it works for me ![]() I’m not using dollars and I also don’t like to have the currency symbol on each invoice line. I am just sending
I’m not using dollars and I also don’t like to have the currency symbol on each invoice line. I am just sending False in the function so you don’t get the currency symbol but only the formatted number so you have to add the currency symbol yourself. But this should be a general implementation so this escaping should be fixed.
That said, below you can find the template. I left out the taxes because in the demo there are no taxes, but I am pretty sure you know more about LaTeX then I do so it shouldn’t be a problem for you to add this.
The LaTeX template
{%for invoice in records %}
${set_lang(invoice.party.lang)}
\documentclass[11pt]{article}
\usepackage[a4paper,hmargin=1cm,vmargin=1cm]{geometry}
\usepackage[parfill]{parskip} % Do not indent paragraphs
\usepackage{longtable}
\usepackage[table]{xcolor}
\usepackage{lastpage}
\linespread{1.5} % Line spacing
\pagestyle{empty} % No page numbers
\begin{document}
%----------------------------------------------------------------------------------------
% Party details move it to the right
%----------------------------------------------------------------------------------------
{\addtolength{\leftskip}{11cm}
{% for line in invoice.invoice_address.full_address.split('\n') %}\
${line} \\\\
{% end %}\
{% if invoice.party_tax_identifier %}\
${invoice.party_tax_identifier.type_string} : ${invoice.party_tax_identifier.code}
{% end %}
}
%----------------------------------------------------------------------------------------
% What kind of invoice is this
%----------------------------------------------------------------------------------------
\centerline{
{% if invoice.type == 'in' %}\
\Large\underline{\bf{Supplier Invoice No: ${invoice.number and '' + invoice.number or ''}}}
{% end %}\
{% if invoice.type == 'out' %}\
{% choose %}\
{% when invoice.state == 'draft' %}\
\Large\underline{\bf{Draft Invoice}}
{% end %}\
{% when invoice.state == 'validated' %}\
\Large\underline{\bf{Pro Forma Invoice}}
{% end %}\
{% otherwise %}\
\Large\underline{\bf{Invoice No: ${invoice.number and '' + invoice.number or ''}}}
{% end %}\
{% end %}\
{% end %}\
}
%----------------------------------------------------------------------------------------
% Invoice details
%----------------------------------------------------------------------------------------
Description: ${invoice.description or ''} \\\\
Reference: ${invoice.origins or ''} \\\\
Date: ${format_date(invoice.invoice_date or today, invoice.party.lang)}
{% if invoice.tax_identifier %}\
\\\\${invoice.tax_identifier.type_string}: ${invoice.tax_identifier.code}
{% end %}\
%----------------------------------------------------------------------------------------
% Build the list of invoice lines. First describe the header, then add the lines
%----------------------------------------------------------------------------------------
\setlength\LTleft{0pt}
\setlength\LTright{0pt}
\begin{longtable}{|p{7cm}|p{2.5cm}|p{2.5cm}|p{2.5cm}|p{2.5cm}|}
\hline
\rowcolor[HTML]{cccccc}
\multicolumn{1}{|l|}{\bf Description}
& \multicolumn{1}{r|}{\bf Quantity}
& \multicolumn{1}{r|}{\bf Unit Price}
& \multicolumn{1}{c|} {\bf Taxes}
& \multicolumn{1}{r|}{\bf Amount} \\\\*
\hline\hline
\endfirsthead
{\bf Description} & {\bf Quantity} & {\bf Unit Price} & {\bf Taxes} & {\bf Amount} \\\\*
\hline\hline
\endhead
\endfoot
\hline
\endlastfoot
{% for line in invoice.lines %}\
{% choose %}
{% when line.type == 'line' %}\
{% if line.product %}\
${line.product.rec_name}
{% end %}\
{% if line.description %}\
{% for l in line.description.split('\n') %}
\\\\${l}
{% end %}\
{% end %}\
& \multicolumn{1}{r|}{${ (format_number(line.quantity, invoice.party.lang, digits=line.unit_digits) + (line.unit and (' ' + line.unit.symbol) or '')) or '' }}
& \multicolumn{1}{r|}{${ format_currency(line.unit_price, invoice.party.lang, invoice.currency, digits=line.__class__.unit_price.digits[1]) }}
& \multicolumn{1}{c|}{-}
& \multicolumn{1}{r|}{${ format_currency(line.amount, invoice.party.lang, invoice.currency) }} \\\\
{% end %}\
{% when line.type =='subtotal' %}
\multicolumn{4}{l}{%
{% for description in (line.description or '').split('\n') %}
${description}
{% end %}
} & ${line.amount} \\\\
{% end %}\
{% when line.type == 'title' %}\
{% for description in (line.description or '').split('\n') %}\
\\\\${description}
{% end %}
{% end %}\
{% otherwise %}
{% for description in (line.description or '').split('\n') %}\
\\\\${description}
{% end %}
{% end %}\
{% end %}
{% end %}\
\end{longtable}
\begin{table}[h]
%----------------------------------------------------------------------------------------
% tax table
%----------------------------------------------------------------------------------------
\begin{tabular}{ |p{2cm}|p{2cm}|p{2cm}| }
\hline
\rowcolor[HTML]{cccccc}
\multicolumn{1}{|l|}{\bf Tax}
& \multicolumn{1}{r|}{\bf Base}
& \multicolumn{1}{r|}{\bf Amount} \\\\*
\hline
\end{tabular}
\hfill
%----------------------------------------------------------------------------------------
% Totals table
%----------------------------------------------------------------------------------------
\begin{tabular}{ p{4cm}|p{5cm}| }
\hline
\multicolumn{1}{|r|}{\cellcolor[HTML]{cccccc}{\bf Total (excl. taxes):}}
& \multicolumn{1}{r|}{${ format_currency(invoice.untaxed_amount, invoice.party.lang, invoice.currency) }}\\\\*
\hline
\multicolumn{1}{|r|}{\cellcolor[HTML]{cccccc}{\bf Taxes:}}
& \multicolumn{1}{r|}{${ format_currency(invoice.tax_amount, invoice.party.lang, invoice.currency) }}\\\\*
\hline
\multicolumn{1}{|r|}{\cellcolor[HTML]{cccccc}{\bf Total:}}
& \multicolumn{1}{r|}{${ format_currency(invoice.total_amount, invoice.party.lang, invoice.currency) }}\\\\*
\hline
\end{tabular}
\end{table}
\thepage \hspace{1pt} of \pageref{LastPage}
\end{document}
{% end %}
I really appreciate any comment on the template!
Hi @edbo,
Your progresses on the topic look very promissing.
If we want to have this as part of tryton we will need to fix the scapping issues and decide which command we run to do the conversion (or if we make it configurable)
For building I’m wondering if it won’t be better to delegate the work to a Python wrapper which should take care about all the commands needed to execute.
This should be an optional library like weasyprint
I think the integration of third party rendering library (weasyprint, latex) should be made more pluggable.
I haven’t put much thoughts about it but I don’t think adding cases after cases is a good idea.
At least for overlapping feature. For now soffice and weasyprint are not overlapping (the soffice html → pdf is not really usable).
But I think the API is enough modular to allow a module to extend the Report.convert to implement its own converter.
Indeed it is already plugable since Mixins not applied to default report class (#9531) · Issues · Tryton / Tryton · GitLab
Anyone can register a mixin that apply for all Report classes.
So we allow overriding the convert from any module.
I want to stay as close as possible to the default Tryton. Load the template use Genshi to put the data into it (translations are added etc) and call an external application to render the document. The wrapper you mentioned does exactly the same as the command I’m using in the convert function. But the wrapper have also the possibility to create your own templates, which I don’t need.
So I’m going the direction of how soffice is called and make some details configurable.
So this means I can create my own module which implements this.
The escaping to twofold:
- load the template itself and escape the double slashes
- load the data from Tryton and escape the $
I have to dig a bit deeper about those two. If I can create my own module this can be a bit easier.
I created my own module and registered a new report mixin. Now I’m able to modify the convert function in my module. But I’m struggling a bit with the escaping. Python itself already starts to escape things (https://docs.python.org/3/reference/lexical_analysis.html#literals) so I changed the rendered report [1] to a raw string and then escape some LaTeX special characters. However that doesn’t feel robust and can fail easily. The code I’m using now:
escaped_data = (r'{}'.format(data)
.replace(r'\*', r'\\*')
.replace('\\\n', '\\\\')
.replace(r'$', r'\$')
)
The last one can break easily, what if there is already a '\'? The second one only escapes the double slashes at the end of a line. But you can have double slashes inside text as well. Is using regular expressions a better idea?
- The rendered report is the LaTeX template filled with Tryton data which is ready to be converted into a PDF.
Are you aware of this library?
https://jeltef.github.io/PyLaTeX/current/pylatex/pylatex.utils.html
It has some utils for escaping latex.
The problem with those libraries is that they are not working for a complete, ready to be converted LaTeX file. They work for inputted data which have to go into the document. Also the document structure is made by those libraries. Also they are checking and escaping way to much.
So I decided to move away from Genshi and relatorio and use Jinja to do the work. I came across http://eosrei.net/articles/2015/11/latex-templates-python-and-jinja2-generate-pdfs and using this with some changes I was able to write a ‘normal’ LaTeX template and add the different blocks for the data from Tryton. The only part left is the escaping of the different functions like format_number, format_date and format_currency. The latter gives an error now because of the unescaped dollar sign.
Another part is getting translations work.
I do not see why Jinja would be more suitable than Genshi.
Any way Relatorio has already a template for pdf which uses texexec to convert .tex into PDF. I guess it will just be a matter to activate it in trytond.
As it is not a very much used feature of relatorio, it may require some improvement probably by escaping the evaluation result. Relatorio will welcome such improvement.
At first I had the same idea, so I digged into Genshi and tried a lot but without luck.
Unfortunately it’s harder because of the translation system. When you want to update the translations Tryton will also read all the reports and tries to get the strings which can be translated.
After spending some hours to get LaTeX working with Genshi and failed, I decided to move to Jinja.
Why is Jinja more suitable:
- Loading the LaTeX template into memory Python or Genshi is automatically escaping the different special characters. Jinja has the possibility to disable escaping (no idea how they do it, but it works flawlessly).
- Writing the generated document to a LaTeX file Python or Genshi is again escaping and removing special characters. From characters like
//or//*the first/is removed which causes an error when the file is processed. Because of the disabled escaping Jinja outputs a perfect LaTeX file - With Jinja you can change the default strings for variables, blocks etc. This makes it possible to have kind of the same syntax for LaTeX. I know not much of a ‘more suitable’ but I want to mention it.
- Because LaTeX templates are plain text, Genshi doesn’t know which text is translatable. Jinja has an i18n extension which makes it possible to enclose your strings which should be translated. This makes is easier for the user, but also keeps the translation a bit more clean because characters like
#,:or&can be left outside the enclosing and out of the translation. - very simple
escapefilter for the dynamic data which can be called by the user.
For me, loading the template and outputting it into a faultless LaTeX file was the biggest issue. By moving to Jinja this was working right out of the box. Also the possibility to change the start and endstrings of the different blocks and variables made the template more readable. In the end translation setup was very easy.
I’ve looked into that as well, but walked into the same problem with escaping.
My code including comments and empty lines is now around 200 lines. This includes:
- adding MIME type
- adding LaTeX to the selection in the UI
- own translate factory (unfortunately needed because Jinja wants
gettextandngettextfunctions) - extend the
TranslationSetwizard to get the translatable strings - report mixin to escape data, render and convert the template into a document
I have to clean up things and make parts more configurable before I release it so it can be tested.
I do not understand that. The basic.tex example shows clearly that Genshi does not break the syntax.
This is also possible with Genshi.
It is explicitly documented that on plain text, it must use gettext: Genshi: Internationalization and Localization
Now it will be a good improvement for Tryton if the Report and Translation used the proper mechanism for plain text.
I do not see the point as it is to escape string for HTML.
Too bad it could have been part of the standard Tryton with probably less effort and improving Tryton.
Please do some research what LaTeX actually is and how a LaTeX file looks like. From the man-page of texexec:
texexec, a ruby(1) script, is the command-line front end to the ConTeXt typesetting system.
And ConTeXt - Wikipedia . So the basic.tex is NOT a LaTeX file, but a ConTeXt file which has another markup then LaTeX.
I couldn’t find anything about this. With Jinja I set the different variables
JINJA_SETTINGS = Environment(
autoescape = False,
block_start_string = r'\BLOCK{',
block_end_string = r'}',
variable_start_string = r'\VAR{',
variable_end_string = r'}',
comment_start_string = r'\#{',
comment_end_string = r'}',
line_statement_prefix = r'%%',
line_comment_prefix = r'%#',
trim_blocks = True,
extensions = ['jinja2.ext.i18n']
)
So in my template I can use
\VAR{ record.line.product.rec_name }
\BLOCK{ for line in record }
\VAR{ line.name }
\BLOCK{ endfor }
Can I change the {% and %} into \BLOCK{ and } in Genshi?
Did look into this one and with minor changes it can work with gettext in plain text templates.
This function only escapes the LaTeX special chars
@classmethod
def _escape_data(cls, value):
"""
The special characters are:
\ = command character
{ = open group
} = end group
& = table column separator
# = parameter specifier
% = comment character
_ = subscript
^ = superscript
~ = non-breakable space
$ = mathematics mode
"""
return (value.replace(r'{', r'\{')
.replace(r'}', r'\}')
.replace(r'&', r'\&')
.replace(r'#', r'\#')
.replace(r'%', r'\%')
.replace(r'_', r'\_')
.replace(r'^', r'\^')
.replace(r'~', r'\~')
.replace(r'$', r'\$')
)
So when you wan to print the dollar currency symbol, it will be escaped so LaTeX sees it as text and not a command.
Again, this is pure LaTeX no ConTeXt. It needs another approach to get it working.
It all started because of the page subtotals in LaTeX. I’m not an experienced developer like you, so I take my time to understand things, take some different approaches to the problem. But I don’t want to waste too much time on something which I can’t get to work like escaping with Genshi. That’s why I putted it into a module with one file as a proof-of-concept to get it working. I hope that parts or the whole module can be integrated, but that’s too much for me and guidance is needed for that.